Learning rate, Data preprocessing, Overfitting
[Learning rate] Gradient

데이터를 통해 모델을 만들어갈 때 Learning rate와 Gradient의 연관 관계를 통해 최적의 모델 값을 찾을 수 있다.
-> Learning rate는 모델을 만들 때 필요한 설정 값인 hyper-parameter라고 할 수 있다.
[Learning rate] Good and Bad
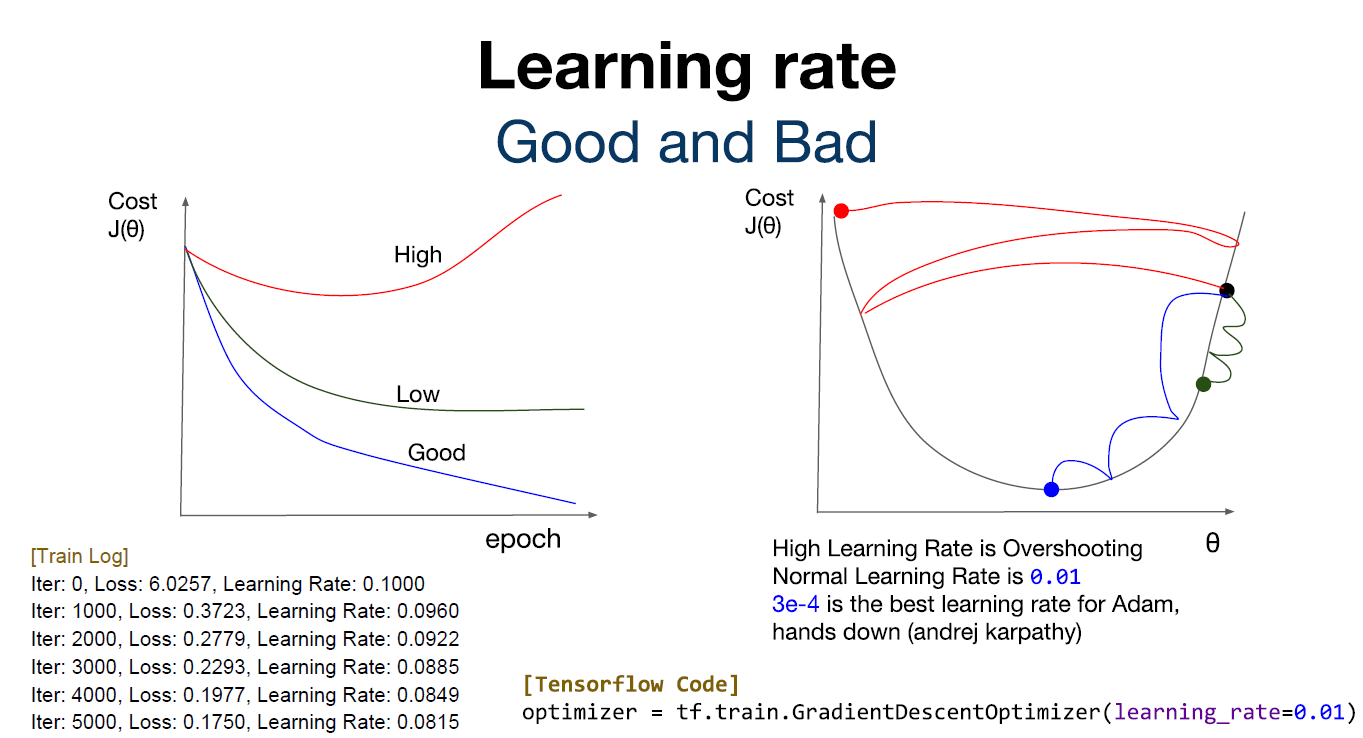
Learning rate를 설정하는 값에 따라 학습할 때 다양한 값들이 나오게 된다.
1. Learning rate가 클 경우, Overshooting이 일어날 수 있다.
2. Learning rate가 작을 경우, 너무 많은 시간이 소비된다.
따라서 적절한 값의 Learning rate를 설정해 원하는 모델의 값을 빨리 찾아내는 것이 중요하다.
-> 일반적으로 사용하는 Learning rate의 값은 0.01
[Learning rate] Annealing the learning rate
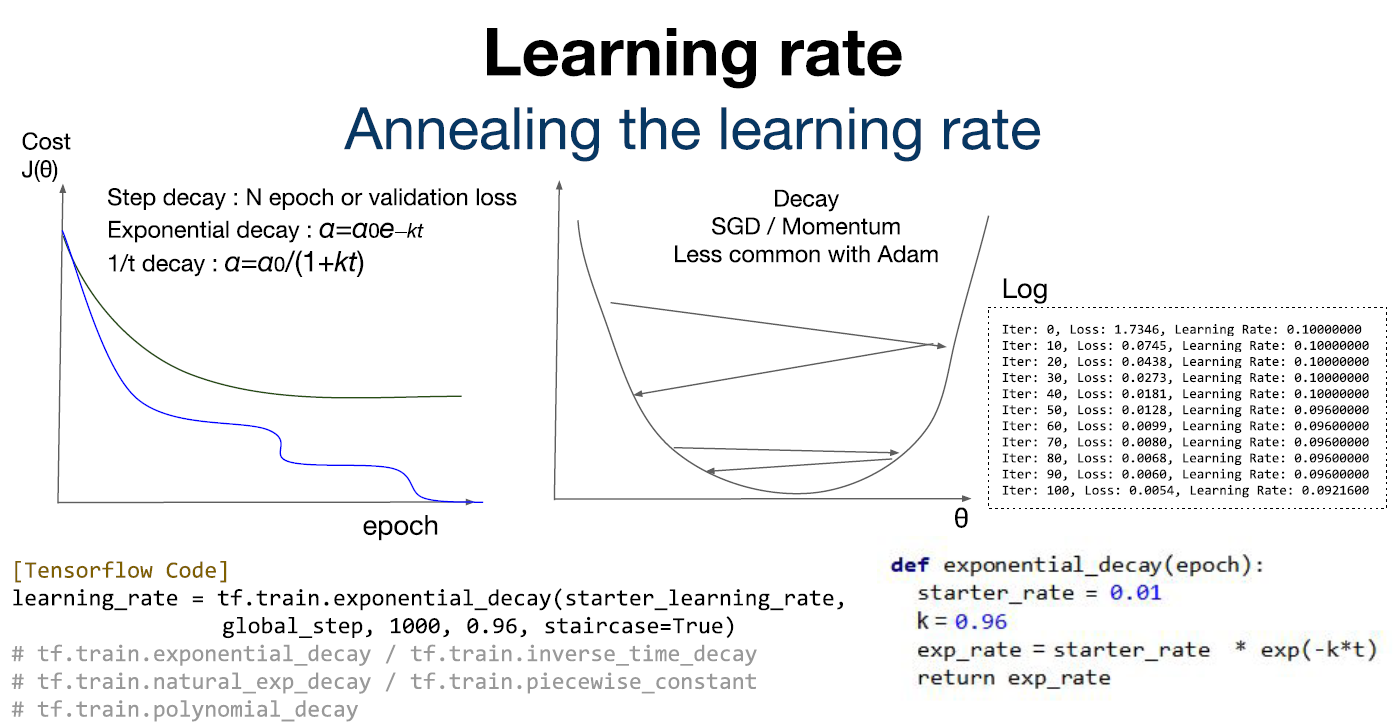
적절한 값의 Learning rate를 구했다 하더라도 학습을 하는 과정에서 Learning rate의 값을 조절하는 것이 필요하다. 학습을 하는 과정에서 Cost 값이 점점 감소하다 더 이상 감소하지 않는 지점(더 이상 학습이 되지 않는 지점)이 있기 때문에 Learning rate의 값을 조절함으로써 더 이상 학습이 되지 않는 지점에서 벗어날 수 있게 만들어준다. 이를 Learning rate decay 기법이라고 한다. Learning rate decay 기법으로는 Step decay, Exponential decay, 1/t decay 기법들이 존재한다.
[Data preprocessing] Feature Scaling

데이터 전처리를 어떻게 진행할 것인가?
소수의 데이터 대신에 실제 많이 분포되어 있는 데이터들을 집중적으로 다루기 위해 표준화 기법과 정규화 기법을 사용하여 표현한다. 표준화를 통해 평균으로부터 얼마나 떨어져 있는지 나타내고, 정규화를 통해 데이터를 0과 1 사이에 고르게 나타낼 수 있도록 한다. 수치형 데이터, 자연어 데이터, 이미지 데이터 모두 적용이 가능하다.
[Overfitting] Set a features
모델을 만드는 과정에서 사용한 데이터에 맞게 모델링이 진행되다 보니 모델링에 사용되지 않은 데이터로 테스트하게 될 경우 정확도가 떨어지는 현상이 나타난다.
1. High bias (underfit): 학습이 덜 된 상태여서 정확하지 않은 모델이 만들어짐
2. High variance (overfit): 학습이 너무 많이 된 상태여서 해당 데이터에만 맞도록 모델이 만들어짐
-> Overfitting은 High variance (overfit)에 관한 문제이다.

features를 어떻게 설정하는지에 따라 Overfitting 문제를 해결할 수 있다.
1. Get more training data
학습을 진행할 때 더 많은 데이터를 입력 값으로 준다. 데이터를 많이 넣음으로써 많은 변화량을 줘도 이를 희석시킬 수 있다.
2. Smaller set of features
2차원에 있는 데이터를 1차원으로 재배치하여 각각의 데이터가 가지는 속성의 의미를 분명히 한다. 데이터를 학습시킬 때 속성의 의미를 통해 모델을 더 잘 찾을 수 있다.
3. Add additional features
모델 자체가 너무 간단하면 모델의 의미가 없기 때문에 의미가 있는 features들을 더 추가하여 모델을 구체화해야 한다.
[Overfitting] Regularization (Add term to loss)

학습하는 과정에서 loss 값에 특정 값을 추가하여 정규화를 할 수 있다. 즉, 람다를 통한 모델의 평균 값을 추가하여 수치 차이가 크게 나는 데이터에 대해서 정규화 한 효과를 준다. 이를 통해 Overfitting을 방지할 수 있다.
[Overfitting] Solutions
1. Feature Normalization: 특징들을 정규화 하기
2. Regularization: loss 값에 특정 값을 추가하여 정규화 하기
3. More Data (Data Augmentation): 데이터를 추가함
4. Dropout (0.5 is common)
5. Batch Normalization
Code (Eager)
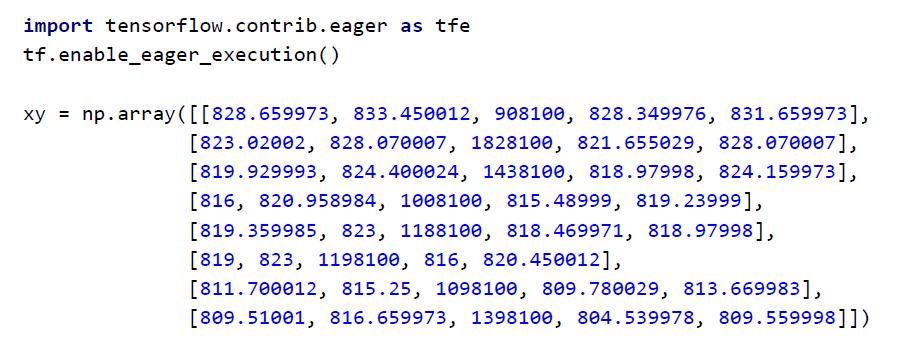
1. 학습을 위한 데이터인 xy는 분포가 큰 데이터이다.

2. xy 데이터를 normalization() 함수에 입력 값으로 주게 되면 가공을 거쳐 0과 1 사이의 구간에 재배치된다.

3. 정규화 된 xy 데이터를 dataset으로 지정하여 반복적으로 학습을 수행한다.

4. l2_loss() 함수를 통해 loss 값에 특정 값을 추가하여 정규화를 수행한다.

5. tf.train.exponential_decay()를 통해 Learning rate decay 기법을 적용한다.
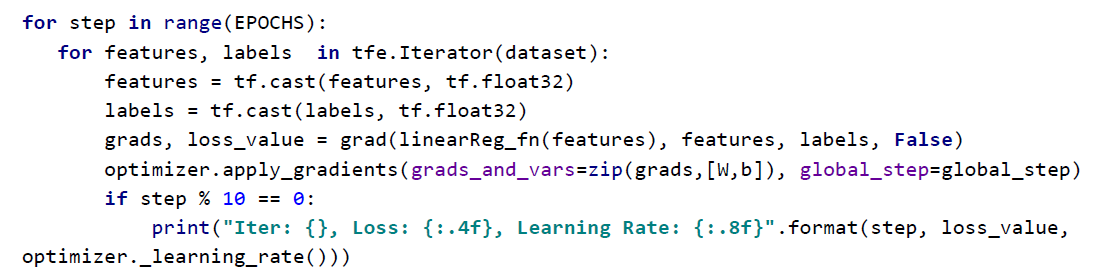
6. Step 별로 진행하면서 Learning rate 값을 조절한다.
Data & Learning
[Data sets] Training and Validation
Training: 학습을 위한 데이터
Validation: 평가를 위한 데이터
Testing: 모델 구성 후에 test를 하기 위한 데이터
데이터의 구성 요소에 따라 학습의 결과가 달라진다. 따라서 데이터를 적절히 구성한 다음에는 네트워크 구조와 Hyper Parameter의 값을 바꿔가며 모델의 성능을 올리는 과정을 반복적으로 수행한다.
[Data sets] Evaluation a hypothesis

어느정도 모델이 선택된 후에는 사용되지 않은 데이터를 통해 test를 진행한다. 왼쪽 사진으로 학습을 진행했을 때, test 데이터로 주어진 오른쪽 사진이 동일 인물인지 판단할 수 있어야한다.
[Data sets] Anomaly detection
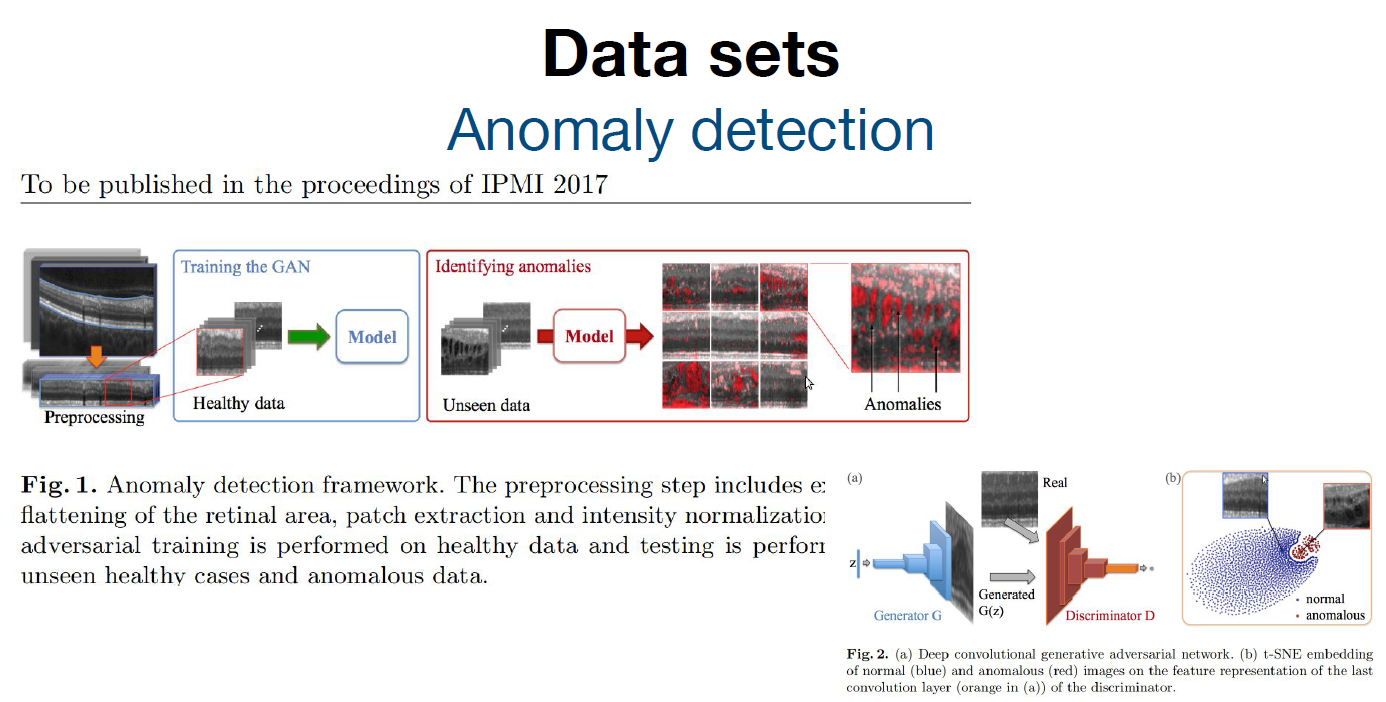
학습을 위한 데이터와 평가를 위한 데이터로 모델을 만드는 것이 아닌, 이상 감지를 통해 모델을 만든다.
1. 정상적인 값을 가지는 데이터로만 학습을 진행한다.
2. 정상적이지 않은 이상 데이터를 입력 값으로 받게 되면 이를 Anomaly로 detection 한다.
[Learning] Online vs Batch
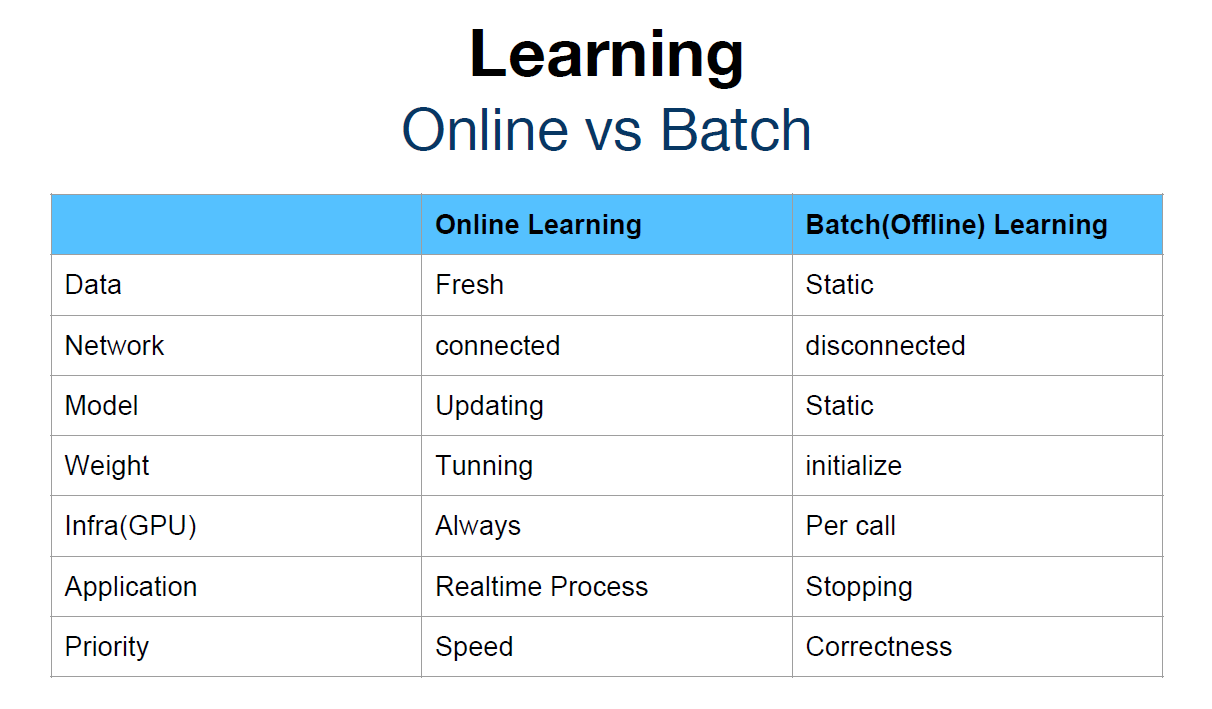
Online Learning: 데이터가 인터넷에 연결된 상태로 지속적으로 바뀌면서 학습을 진행한다.
Batch (Offline) Learning: 데이터가 인터넷에 연결되지 않은 상태로 고정된 값으로 학습을 진행한다.
[Learning] Fine Tuning / Feature Extraction
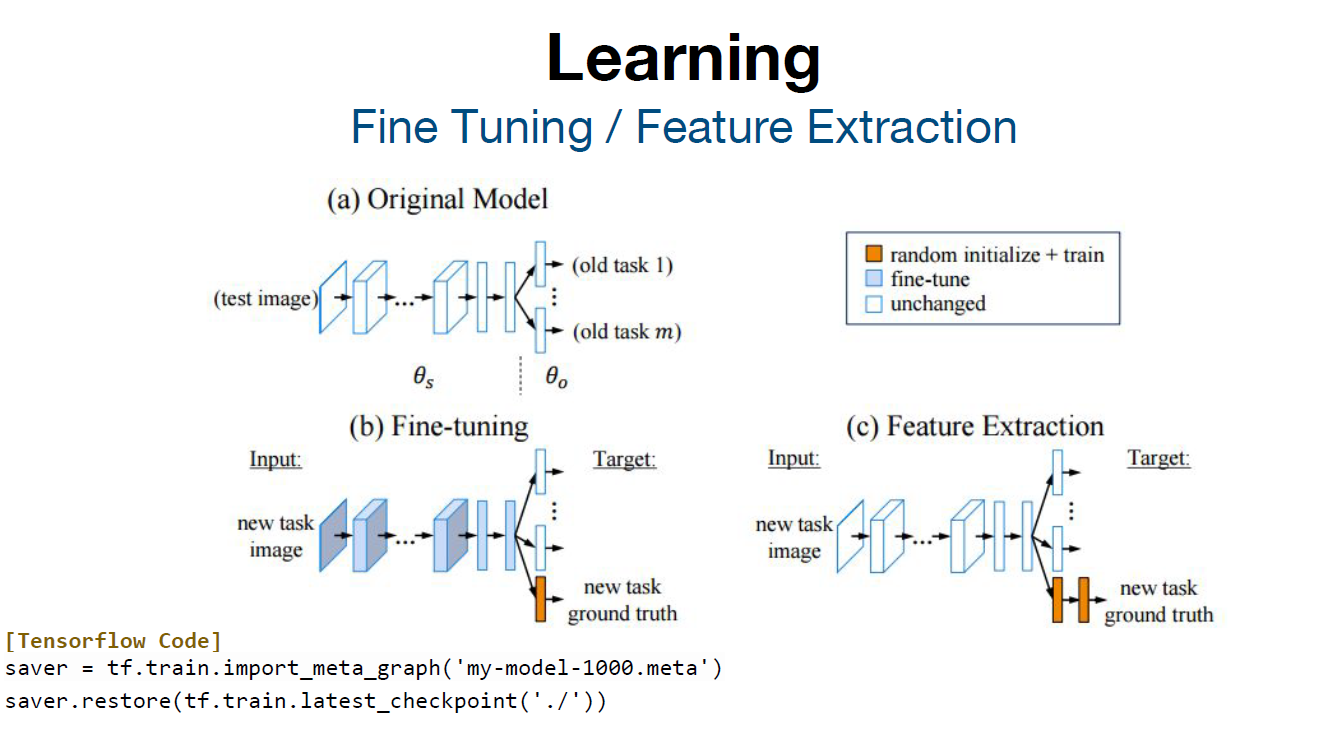
Fine Tuning: 기존에 학습되어져 있는 Original Model을 기반으로 새로운 목적에 맞게 모델의 구조를 변형하고, 이미 학습된 모델의 가중치를 미세하게 조정하여 학습시키는 방법을 말한다
Feature Extraction: 기존에 학습되어져 있는 Original Model을 기반으로 새로운 features들을 생성하는 방법을 말한다.
[Learning] Efficient Models
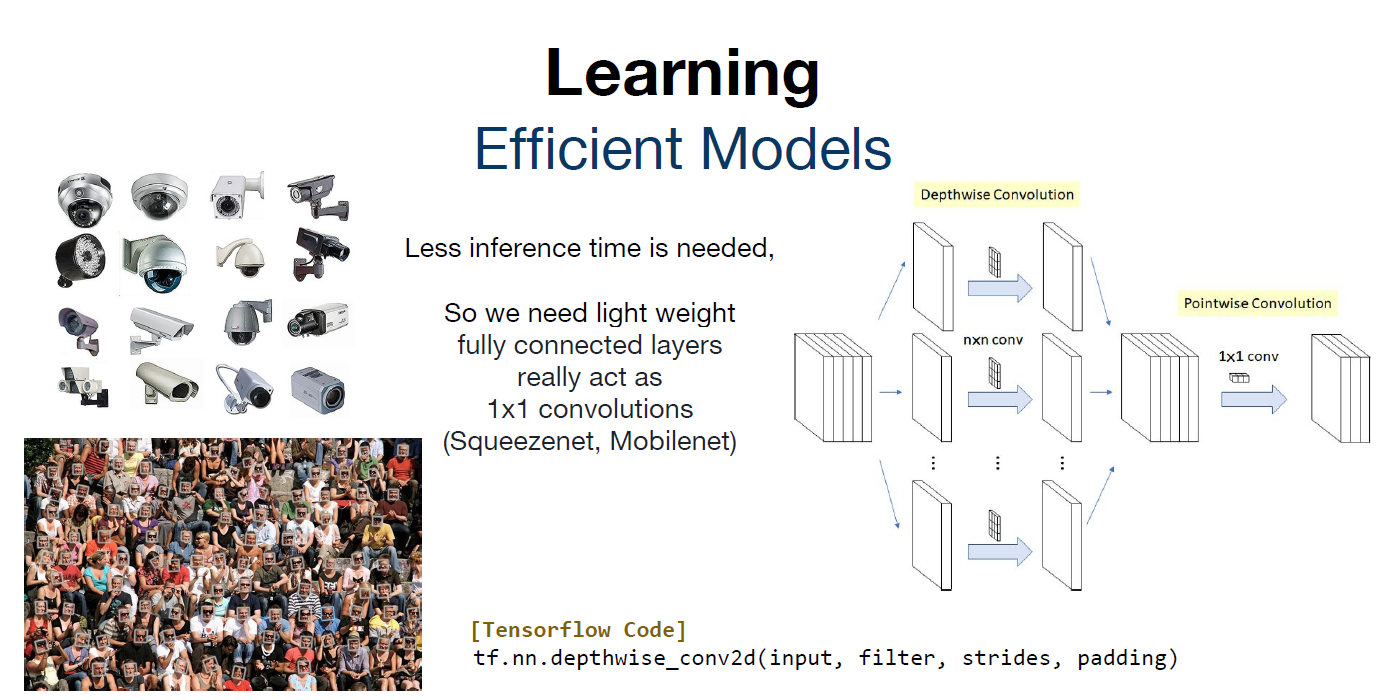
1. 효과적인 모델을 만들기 위해서는 inference time을 최소화하고, 모델의 가중치를 경랑화 하는 것이 중요하다.
2. fully connected layers에 대한 파라미터 값이 많기 때문에 이를 1x1 convolutions으로 대체하여 사용한다.
[Sample Data] Fashion MNIST-Image Classification
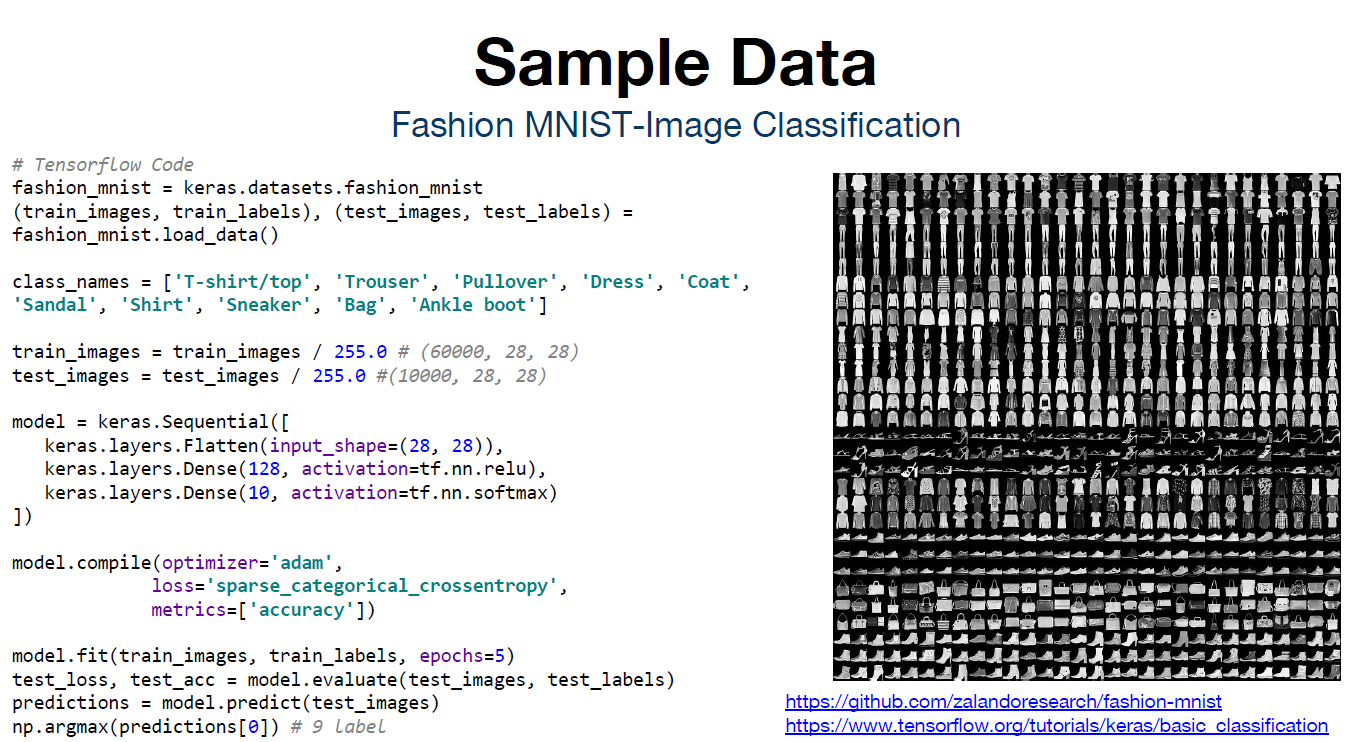
의류 이미지를 구분하는 예제
1. 255.0 사이즈를 가지는 이미지를 0과 1 사이의 값으로 정규화 하는 과정을 거친다.
2. 128개의 layer를 선언하고, 10개의 class로 구분하는 모델을 만든다.
3. optimizer, loss, metrics 값을 설정한 뒤에 컴파일을 진행한다.
4. fit() 함수를 통해 모델을 훈련시킨다.
5. 훈련된 모델에 test 데이터를 집어넣어 loss, accuracy 값을 출력한다.
[Sample Data] IMDB-Test Classification

영화 리뷰를 분류하는 예제
1. 자연어를 사용하기에 단어의 전처리가 매우 중요하다. 공백, 시작, 모르는 단어, 사용되지 않은 단어를 벡터로 각각 분류한다.
2. 전처리가 끝난 단어를 train_data로 지정한다.
3. optimizer, loss, metrics 값을 설정한 뒤에 컴파일을 진행한다.
4. fit() 함수를 통해 모델을 훈련시킨다.
[Sample Data] CIFAR-100

CIFAR-10을 100개의 class로 확장시켜서 데이터를 가져와 test를 수행하는 예제
'스터디 > 모두를 위한 딥러닝 시즌 2' 카테고리의 다른 글
| XOR 문제 딥러닝으로 풀기 (0) | 2023.08.13 |
|---|---|
| 딥러닝의 기본 개념 (0) | 2023.08.13 |
| Softmax Classifier (0) | 2023.08.06 |
| logistic_regression (0) | 2023.08.06 |
| Multi variable linear regression (0) | 2023.07.30 |



