[Problem of Sigmoid]
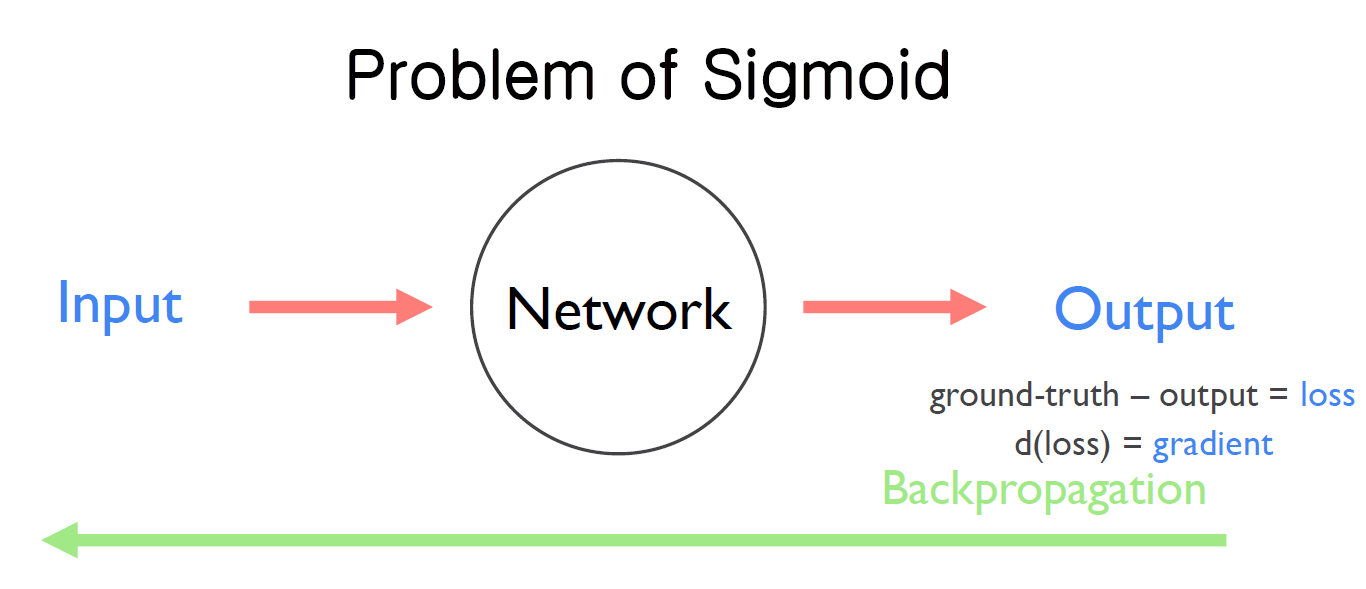
1. Network에 데이터를 입력해서 나온 output과 ground-truth 값의 차인 loss를 구한다.
2. 구한 loss 값의 미분 값을 Backpropagation 해서 Network를 학습시킨다. 이때 Backpropagation으로 전달되는 loss를 미분한 것을 gradient라고 한다.
3. gradient 값은 그래프의 기울기 값이라고 할 수 있는데, sigmoid 함수 그래프의 가운데 부분은 0보다 매우 크다. 반면에 극단 좌표의 gradient값은 0에 가까워 매우 작다.

4. Network가 deep할 경우 sigmoid 함수가 많아지고, 매우 작은 gradient 값들이 sigmoid 함수의 개수만큼 곱해진다. 결국 gradient 값이 작아져 Network가 전달받을 gradient 값이 소실되는 Vanishing Gradient 상황이 발생한다.
[Relu]

x를 입력 값으로 받았을 때, x가 0보다 큰 양수의 값을 가진다면 그대로 x를 출력 값으로 추출한다. 만약 x가 0보다 작은 음수의 값이라면 0을 출력 값으로 추출한다. 간단하면서도 좋은 성능 향상을 일으키기 때문에 많이 사용하며, 추가적으로 Relu 함수의 음수 문제를 보완하는 leaky relu 함수가 존재한다.
[Code] Load mnist

1. 먼저 data set으로 mnist를 load 한다.
2. eager 모드로 Tensorflow를 실행시킨다.

3. mnist를 load한 뒤, np.expand_dims() 함수를 사용하여 추가적으로 채널을 하나 더 만들어 준다.

4. 이미지들의 값을 255로 나눠서 0과 1 사이의 값으로 만들어 주는 normalize를 진행한다.

5. label들의 개수를 고려하여 One hot incoding을 적용한다.
6. 전처리해주는 과정을 완료한 후에 이미지와 label를 return한다.
[code] Create network
1. network를 구성할 때는 어떤 함수들을 사용할 것인 것 생각해보아야 한다.

2. flatten(), dense(), relu() 3가지 함수들을 사용해서 model을 구성한다.

3. tf.keras.initializers.RandomNormal() 함수를 사용해 평균이 0, 분산이 1인 가우시안 분포로 random 한 weight 값을 설정해준다.
4. dense()와 relu() 함수를 사용하기 위해서 이미지를 flatten() 함수를 사용해 변환시킨다.
5. 파라미터 label_dim로 들어온 값이 mnist이기에 최종적으로 10개의 출력 값을 추출한다.
[code] Define loss

1. loss를 구하는 함수인 loss_fn()을 정의한다. model의 입력 값으로 images를 넣고, images에 해당하는 숫자인 logits를 출력 값으로 추출한다. logitis과 lables의 값으로 softmax function을 사용하여 loss 값을 구한다.

2. 정확도를 구하는 함수인 accuracy_fn()을 정의한다. tf.argmax() 함수를 사용하여 logitis과 lables에서 가장 숫자가 큰 값의 위치를 가져온다. 두 개의 값이 일치하면 true를 return 한다.

3. gradient를 구하는 함수인 grad()을 정의한다. loss에 해당하는 weight들의 gradient를 return 한다.
[code] Experiments (parameters)

1. 위에서 load한 mnist에서 각각의 data 값들을 가져와 hyper parameters의 값을 설정한다.

2. 한 번에 많은 양의 이미지들을 network에 넣는 것이 아니라, data set를 적절히 섞은 후 batch size만큰 이미지를 network에 넣는다.
3. 학습을 진행할 때, prefetch() 함수를 사용해 메모리에 미리 batch size만큼 올려놓아 학습이 더 빠르게 진행하도록 해준다.
4. 해당 과정을 계속 반복한다.
[code] Experiments (model)

hyper parameters를 다 설정한 뒤에 model을 진행한다.
[code] Experiments (Eager model)

최종적으로 Eager mode로 전체적인 학습을 진행한다. 이때, network로 학습을 진행하다 학습이 끊겼을 때 원활한 재학습을 진행하기 위해서 checkpoint을 생성한다. Relu가 Sigmoid보다 더 높은 성능을 보여준다.
'스터디 > 모두를 위한 딥러닝 시즌 2' 카테고리의 다른 글
| Dropout (0) | 2023.08.20 |
|---|---|
| Weight Initialization (0) | 2023.08.20 |
| XOR 문제 딥러닝으로 풀기 (0) | 2023.08.13 |
| 딥러닝의 기본 개념 (0) | 2023.08.13 |
| application and tips (0) | 2023.08.06 |



